국민대학교 기계공학부에서 진행하는 로봇 AI 기초 특강에서 다루는 로봇은 JETBOT입니다. 젯봇의 specification 은 다음과 같으며 라즈베리파이나 라떼판다 등 다른 소형 pc와는 큰 차이점이 있습니다. Nvidia에서 개발한 보드답게 소형 gpu가 탑재되어있어서 여러 딥러닝 네트워크들을 효율적으로 연산이 빠른 gpu를 함께 구동시킬 수 있다는 것이지요.
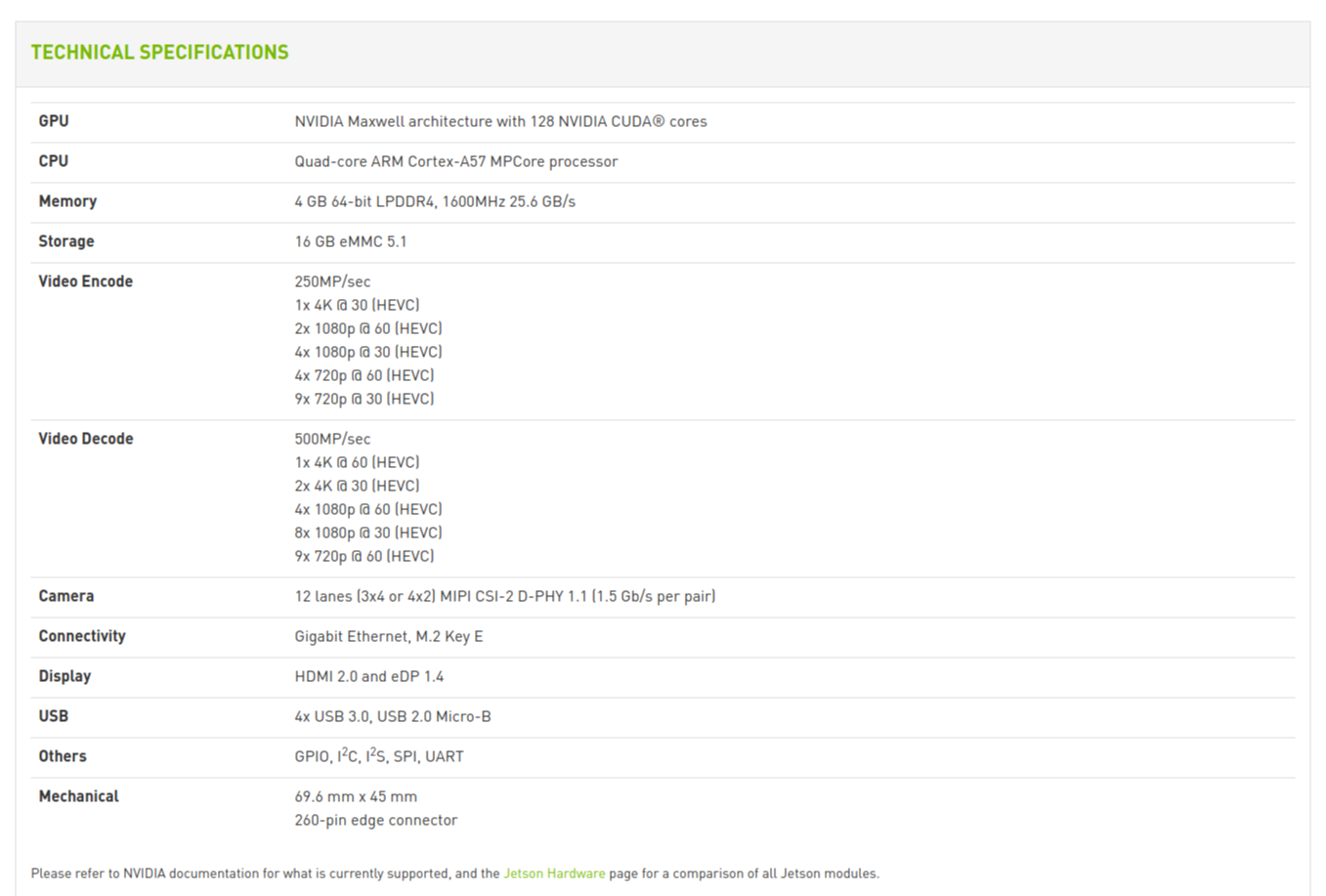

사진에서 보이는것과 같이 설명에 다음과 같은 말이 적혀 있습니다. "최신 인공지능기술을 이제는 메이커, 학생들 그리고 임베디드 개발자들이 어디서든지 사용할 수 있습니다." 이 말은 곧 소형 mcu에서도 이제 인공지능을 위한 데이터셋 구축, 학습 등의 과정을 갖출 수 있다는 것이겠지요. 저희가 이번에 다루게 되는 로봇은 이 개발 키트에다 모터와 무선랜카드 그리고 카메라를 장착시켜서 이미지 객체인식, 환경인식에 따른 조향각 산출 그리고 최종적인 자율주행을 이루는 것을 목표로 합니다. 단순히 선을 따라가는 것에 그친다고 생각할 수도 있지만, 이미지 데이터를 모으고 사용자가 어느 부분을 Look ahead point로 갖고 갈지 정해준다면 이후에는 인공지능이 알아서 이미지의 특징점들을 통해 Look ahead point를 찾아서 나아가는 환경을 만들었다는 것이 흥미로운 부분이 되겠습니다.

이번 글에서는 젯봇을 운용하면서 주요하게 봐야 할 것들을 요약하며 쓰였던 주요 알고리즘들을 나열하고 공부하는 방식으로 진행하겠습니다. 로봇을 구매하고 따라 하고 싶은 분은 깃허브의 Jetbot 내용을 그대로 따라 하시면 되겠습니다.
https://github.com/NVIDIA-AI-IOT/jetbot/
NVIDIA-AI-IOT/jetbot
An educational AI robot based on NVIDIA Jetson Nano. - NVIDIA-AI-IOT/jetbot
github.com
JETBOT의 목차
- Basic Motion
- Tele Operation
- Object Following
- Collision Avoidance
- Road Following
1. Basic motion
젯봇의 기본적인 모터 제어에 관한 부분을 다루고 있습니다. 이후에 있을 road following 쪽에서 자유롭게 코드를 작성하기 위해서는 기본적인 함수의 설정 방식은 알아둬야 할 필요성이 있습니다.
robot.left_motor.value = 0.3
robot.right_motor.value = 0.6
time.sleep(1.0)왼쪽 모터의 출력값과 오른쪽 모터의 출력 값을 정해주는 코드입니다. time함수에서 얼마큼 지속할지에 대한 코드입니다.
2. Tele Operation

이미지와 같이 조종기를 연결하여 입력값을 받는 함수에 관해서 다루고 있습니다. 이후에 데이터 학습과정에서 사진을 찍거나 Look ahead point를 지정할 때 쓰입니다. 조종기를 연결시킬 때 home버튼을 두 번 누르면 더욱 안정적인 연결이 된다고 합니다. (빨간색 불 두 개) 또한 저의 경우에는 로봇을 컴퓨터에 랜으로 연결해서 인터넷에서 ip로 바로 접속한 환경에서 리모컨을 로봇에다 연결하는 것이 아닌 컴퓨터에 연결하였더니 잘 인식하여 로봇에 값을 전달할 수 있었습니다.
from jetbot import Robot
import traitlets
robot = Robot()
left_link = traitlets.dlink((controller.axes[1], 'value'), (robot.left_motor, 'value'), transform=lambda x: -x)
right_link = traitlets.dlink((controller.axes[3], 'value'), (robot.right_motor, 'value'), transform=lambda x: -x)trailets라는 패키지를 활용하여 컨트롤러에서 값을 받아 올 수 있었네요. controller클래스에서 1번, 3번 축의 값을 이용해서 left_link 와 right_link 변수에 입력시키는 함수임을 유추할 수 있습니다. controller class에는 axes와 button 두 종류의 사용자가 선택할 수 있는 입력 방법이 있다는 것을 알고 있길 바랍니다.
3. Object Following
오브젝트 팔로잉은 말그대로 객체를 인식하여 객체의 위치를 및 크기를 파악한 뒤 그 객체를 따라가는 예제입니다. 본 예제에서는 COCO dataset을 이용하여 미리 학습되어있는 neural network를 이용합니다. 텐서 플로의 object detection API를 이용하여 사용자 환경에서의 객체인식을 진행합니다. 2017년 구글에서 배포한 텐서 플로 Tensor Flow Object Detection API의 기능을 모바일 넷을 이용한 학습한 모델인 ssd_mobilenet_v2_coco.engine을 이용한다고 생각하면 되겠습니다. 모바일 넷의 네트워크를 사용하기 때문에 모바일 장치에서 실시간으로 실행이 가능하다고 평가되어 있습니다 [1].
detections = model(camera.value)
print(detections)위의 코드에서 처음에 한 장의 사진을 찍습니다. 그 사진에서 분류된 객체의 크기와 위치를 파악하고 따라가기 때문에 처음에 coco dataset 목록에서 라벨링 된 데이터들 중 하나를 골라서 사진을 찍는 것이 좋겠습니다.
4. Collision Avoidance
하나의 카메라라는 간단하고 값싼 입력장치를 이용해서 마음껏 로봇을 돌아다니게 만들 수 있습니다. 주피터 노트북에서 이와 같은 모든 과정들을 실행할 수 있습니다.
충돌 회피를 뜻하는 collision avoidance는 어느 정도 딥러닝의 모든 과정을 따라갑니다. data_collection.ipynb 에서 데이터를 모아서 데이터 셋을 만들고 train_model.ipynb 에서 모델을 트레이닝하고 live_demo.ipynb 에서 시험합니다.
인공신경망을 학습하여 이미지가 충돌 가능성이 얼마나 있는지, 다시 말해 멈춰야 할 상황인지 아닌지를 판단합니다. 그에 따라서 다양한 데이터셋이 필요로 됩니다. 언제는 계속 나아가도 되는지, 나아가면 안 되는지. 두 개의 클래스를 가진 데이터셋을 이용하여 인공지능이 알아서 충돌할것인지 아닌지를 판단하게 하는것입니다. 하나의 변수에 두개의 분류 방법이 있기 때문에 상대적으로 매우 간단하다고 볼 수 있습니다. 예를 들어 주행환경에서 신호등을 보면 멈추어야 하는 상황이라면, 주행환경에서 신호등이 있을 때와 없을 때를 구분 지어 학습을 시키면 로봇은 신호등이 있을 때만 멈추고 나머지 환경에서는 멈추지 않을 것입니다. 하지만, 여러 주행환경에 적응하도록 하려면 학습 데이터를 그림자가 진상황, 조도에 따라서 등등의 환경변수들을 고려하여 학습 데이터를 모아주어야 할 것입니다.






데이터셋을 다 모은 다음은 PyTorch라는 딥러닝 라이브러리를 이용하여 학습모델을 만듭니다. 데이터의 학습을 위해서 준비과정인 torchvision datasets package를 이용하여 이미지 폴더 데이터셋 클래스를 이용합니다. 그 후 모아진 데이터셋에서 학습 데이터와 테스트 데이터로 분류합니다.
NUM_EPOCHS = 30
BEST_MODEL_PATH = 'best_model.pth'
best_accuracy = 0.0
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(NUM_EPOCHS):
for images, labels in iter(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
test_error_count = 0.0
for images, labels in iter(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
test_error_count += float(torch.sum(torch.abs(labels - outputs.argmax(1))))
test_accuracy = 1.0 - float(test_error_count) / float(len(test_dataset))
print('%d: %f' % (epoch, test_accuracy))
if test_accuracy > best_accuracy:
torch.save(model.state_dict(), BEST_MODEL_PATH)
best_accuracy = test_accuracy다음의 코드를 통해서 학습을 진행합니다. epochs는 학습 횟수( 같은 데이터셋을 여러 번 학습합니다.) 한 번의 epoch마다 best_model.pth 파일이 torch.save의 함수로 만들어집니다. 만들어진 패스 파일의 테스트 정확도가 지금까지의 가장 좋은 정확도보다 좋을 경우 기존의 패스 파일을 대체하는 방식으로 학습이 이루어집니다.
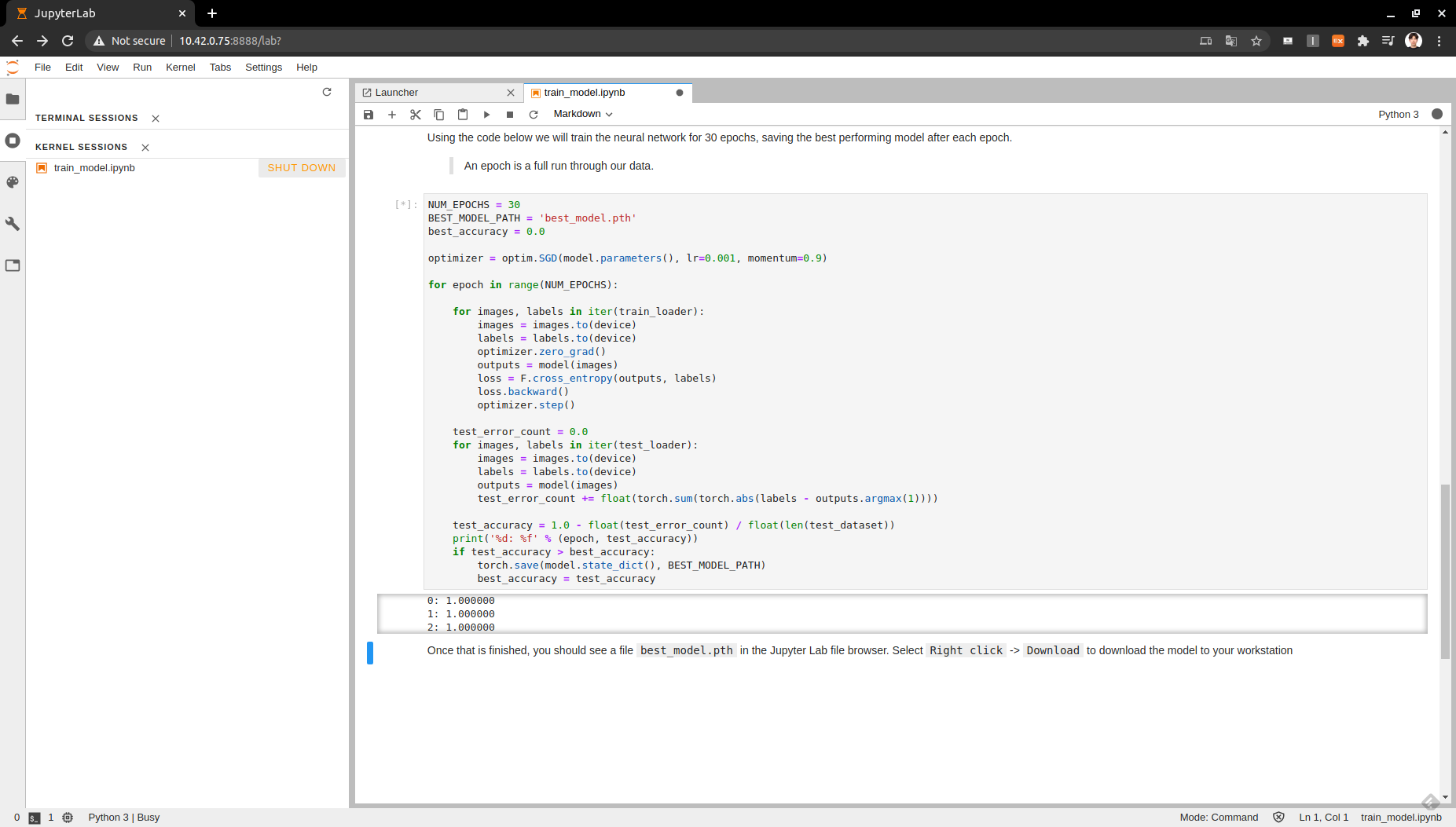
만들어진 패스파일을 이용하여 데이터 분류를 진행하기 위해서는 약간의 전처리 과정을 필요로 합니다. 모델이 필요로 하는 이미지와 포맷이 차이가 있기 때문에 다음의 명령어와 함수로 전처리를 진행합니다.
import cv2
import numpy as np
mean = 255.0 * np.array([0.485, 0.456, 0.406])
stdev = 255.0 * np.array([0.229, 0.224, 0.225])
normalize = torchvision.transforms.Normalize(mean, stdev)
def preprocess(camera_value):
global device, normalize
x = camera_value
x = cv2.cvtColor(x, cv2.COLOR_BGR2RGB)
x = x.transpose((2, 0, 1))
x = torch.from_numpy(x).float()
x = normalize(x)
x = x.to(device)
x = x[None, ...]
return x모든 주피터 노트북의 instruction을 따라 한다면 장애물이 보였을 때와 보이지 않았을 때의 정도를 표현하는 prob_blocked 변수의 슬라이드바가 보일 것입니다. 그 정도를 if문에 적용시켜서 사용자가 원하는 방향으로의 프로그래밍을 하면 되겠습니다.
5. Road Following
실제 자율주행 자동차에서 이와 같은 방식으로 길을 따라간다면 사고가 많이 날 수도 있겠지만, 로봇이기 때문에 이와 같이 실험적인 방법의 딥러닝 네트워크를 통해서 길을 따라갈 수 있다는 것을 보여주는 의미가 큽니다.
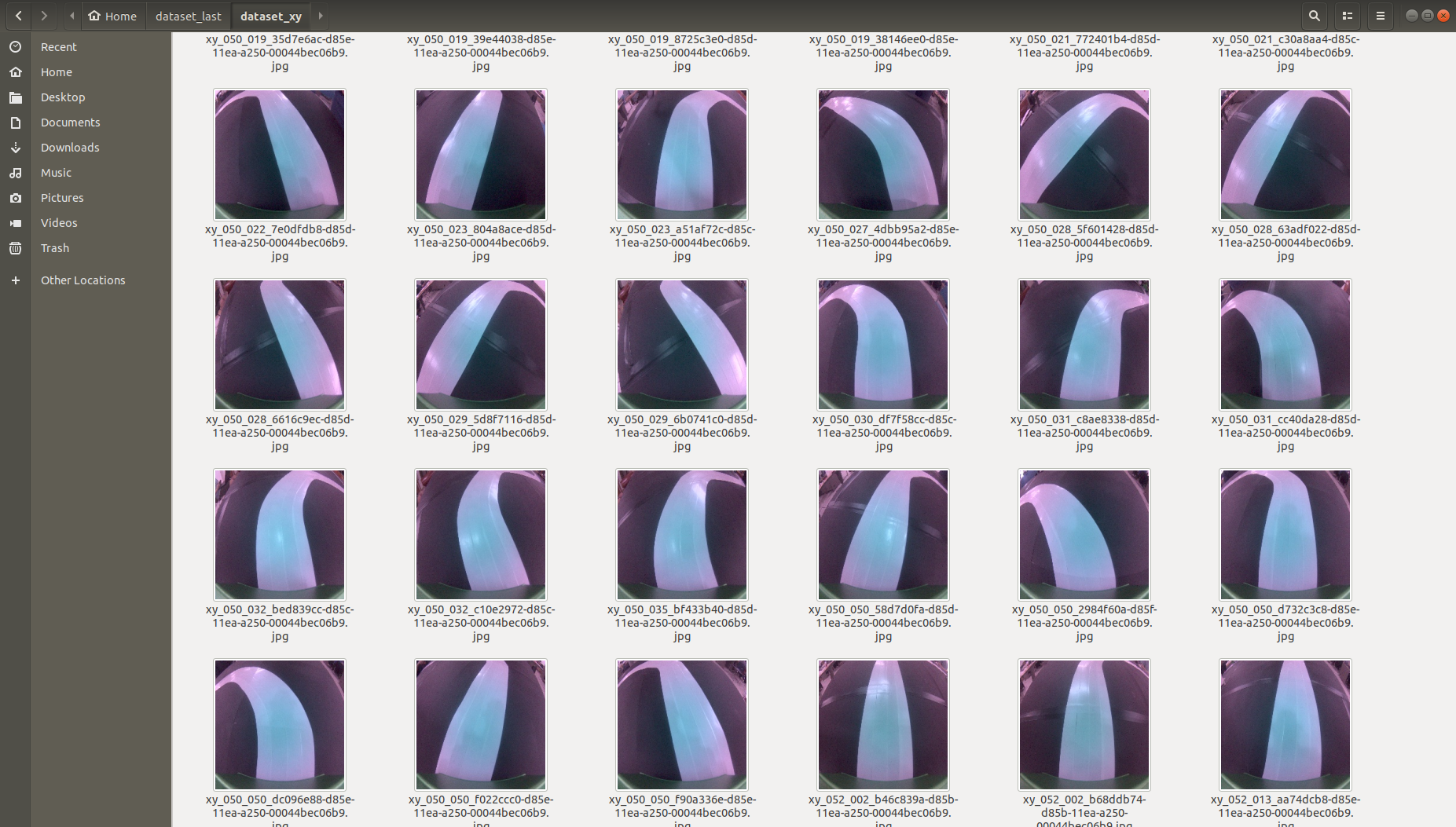
있을 수 있는 데이터들을 모두 모아야 합니다. 사진과 같이 직선구간, 곡선구간, 라인을 이탈했을 경우 등 여러 데이터셋을 이용하여 로봇이 가야 할 방향을 찍어줍니다. 로봇이 가야할 포인트를 우리는 Look ahead point라고 하고 그 포인트를 지정해주면 학습된 모델이 알아서 Point를 지정해주고 로봇을 움직이게 할 것입니다.
https://www.youtube.com/channel/UC7-oyh8n43iwGVfV8vyWUWA
Chitoku Yato NV
www.youtube.com
위와 같이 학습 데이터를 모아줍니다. 다양한 배경에서 환경에서 조도에서, 여러 환경적인 변수에 영향을 받지 않도록 데이터의 다양화가 학습결과에 중요한 영향을 끼칩니다.
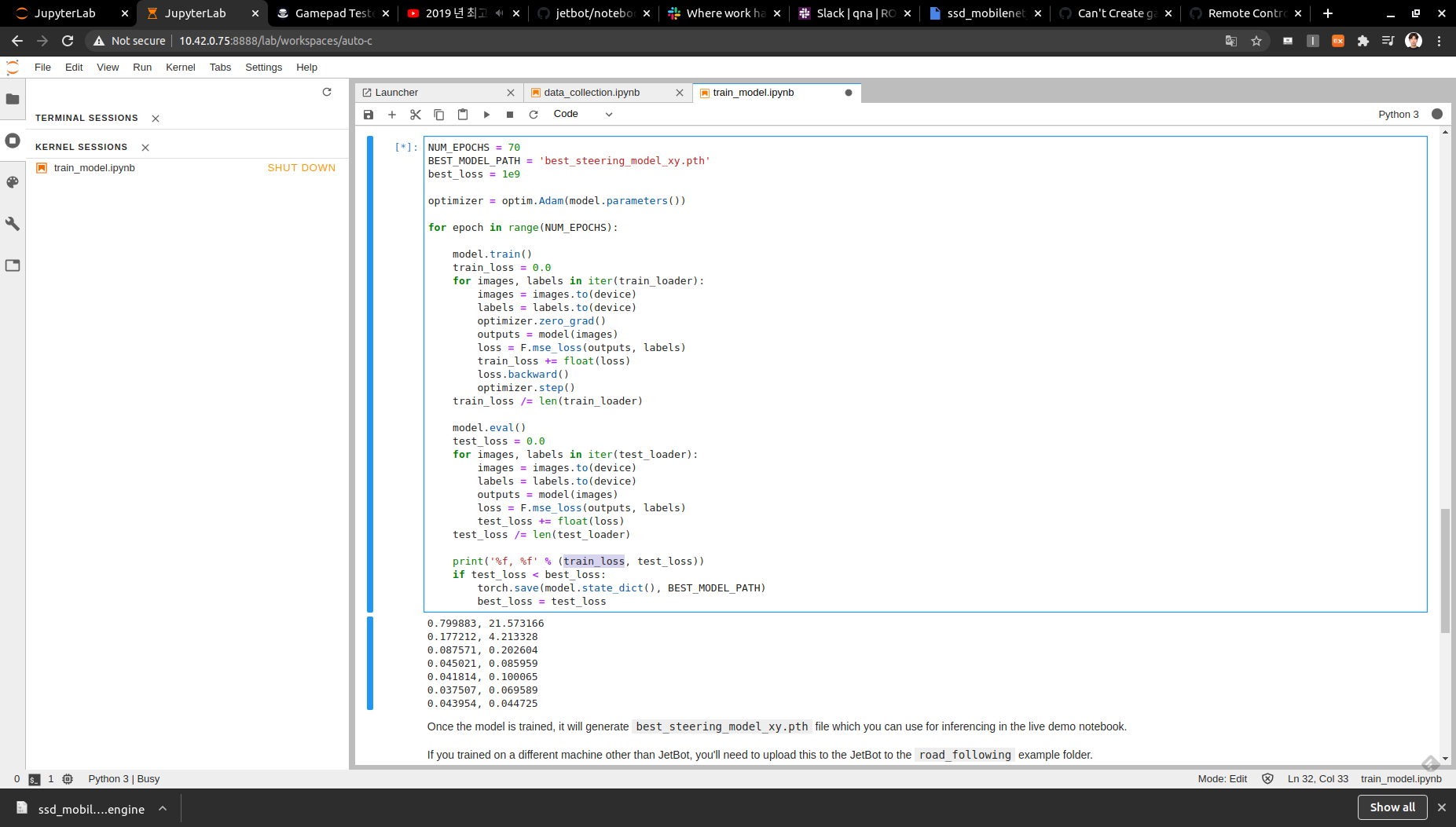
다음의 로봇에는 중요한 문제가 있습니다. 모터의 토크가 높지 않아 저속운행이 불가하다는 점인데, 빨리 가기에는 이미지 프로세싱 능력의 속도가 늦다는 데 있습니다. 따라서 선을 이탈하는 경우가 많습니다. 저희 팀은 이와 같은 문제에 다음과 같은 코드로 d안정적인 주행을 이루었고 결과적으로 학습 데이터의 유효성을 확인하였습니다. 깃허브에 공유해두었던 것을 링크합니다.
https://github.com/NVIDIA-AI-IOT/jetbot/issues/233
[SOLUTION] Road Following not working properly Problem Solution · Issue #233 · NVIDIA-AI-IOT/jetbot
Hi guys. It is my first time talking to people on githubs. As I have got lots of help from github, I would like to share my case how I made it to work. When I followed the instructions in Road foll...
github.com
angle = 0.0
angle_last = 0.0
count_motor = 0
def execute(change):
global angle, angle_last, count_motor
image = change['new']
xy = model(preprocess(image)).detach().float().cpu().numpy().flatten()
x = xy[0]
y = (0.5 - xy[1]) / 2.0
x_slider.value = x
y_slider.value = y
speed_slider.value = speed_gain_slider.value
angle = np.arctan2(x, y)
pid = angle * steering_gain_slider.value + (angle - angle_last) * steering_dgain_slider.value
angle_last = angle
steering_slider.value = pid + steering_bias_slider.value
if count_motor >2:
robot.left_motor.value = max(min(speed_slider.value + steering_slider.value, 1.0)*0.95, 0.0)
robot.right_motor.value = max(min(speed_slider.value - steering_slider.value, 1.0), 0.0)
count_motor = 0
else :
robot.left_motor.value = 0
robot.right_motor.value = 0
count_motor = count_motor + 1
execute({'new': camera.value})speed_gain_slider = ipywidgets.FloatSlider(min=0.25, max=1.0, step=0.01, description='speed gain')
steering_gain_slider = ipywidgets.FloatSlider(min=0.0, max=1.0, step=0.01, value=0.05, description='steering gain')
steering_dgain_slider = ipywidgets.FloatSlider(min=0.0, max=0.5, step=0.001, value=0.0, description='steering kd')
steering_bias_slider = ipywidgets.FloatSlider(min=-0.3, max=0.3, step=0.01, value=0.0, description='steering bias')다양한 gain 값을 가지는데, 스피드 게인은 최대 스피드 값을 결정하고, steering 게인은 스티어링 민감도를 결정합니다. 저희는 이와 같은 값을 정해주었습니다. 로봇마다 차이가 있으니 참고하시길 바랍니다.
다음은 주행 영상입니다.
<참고문헌 및 출처>
1. https://teamlab.github.io/jekyllDecent/blog/object%20 detection/Object-detection-tutoral
2. https://github.com/NVIDIA-AI-IOT/jetbot/blob/master/notebooks/object_following/live_demo.ipynb
'Autonomous Vehicle > ROS programming' 카테고리의 다른 글
| ROS에서 Package 빌드하기 (생성한 후) (0) | 2020.08.12 |
|---|---|
| ROS에서 Package 생성하기 (0) | 2020.08.12 |
| 특강 3일차 : OpenCV ROS 환경에서 구동 (0) | 2020.07.29 |
| 특강 2일차 : Roslaunch에 대한 이해 (0) | 2020.07.24 |
| 특강 2일차 : ROS Package 만들기 (0) | 2020.07.24 |



